Object-Centric Process Mining
Object centric process mining is a process mining approach used when one process involves multiple related business objects instead of a single case.



Object centric process mining is a process mining approach used when one process involves multiple related business objects instead of a single case.
Traditional process mining usually starts with one case, such as one order, one invoice, or one ticket. That works well for many processes, but not for all of them.
In real organizations, one process often involves several connected objects at the same time. A customer order may contain multiple order items. Those items may lead to different deliveries, invoices, or returns. When everything is forced into one case-centric view, some of that structure is lost.
This is where object centric process mining becomes useful. It helps teams analyze processes that are shaped by relationships between several business objects, not just by the sequence of events inside one case.
Object centric process mining is an additional approach to process mining designed for processes that involve more than one important business object. Instead of forcing all events into a single case notion, it keeps the relationships between objects visible in the analysis.
This matters because many operational processes are not truly linear. They include objects that split, merge, or interact in ways that are difficult to represent in a simple case-centric event log.
For example, one sales order may include several order items. Those items may be shipped separately and invoiced at different times. If the analysis tries to treat only the sales order or only the invoice as the case, it can flatten the process in ways that distort what is really happening.
This approach helps avoid that problem by preserving the links between events and the different objects involved. That makes the process representation more realistic and often more useful for understanding complex execution paths.
Traditional process mining usually assumes that one process instance can be represented through one case notion. In many situations, that works well. A support ticket, an insurance claim, or a leave request can often be analyzed as a single case from start to finish.
The challenge appears when the process does not behave like one clean case. Many real business processes include several objects that interact with each other over time. If the analysis forces those relationships into one case-centric view, the result can become simplified in ways that hide how the process actually works.
A case-centric approach assumes that events can be grouped around one main process instance. That instance might be an order, an invoice, or a ticket.
This works best when:
In these situations, the case concept is stable enough to support useful process mining.
Case-centric analysis is often effective in relatively linear processes where the main object is easy to define and where the process does not branch across several connected business objects.
Examples include:
In these types of processes, one case can often explain most of the flow.
The limitation appears when one process involves several related business objects that do not fit naturally into one case. A common example is order-to-cash, where one customer order may contain multiple items, create several deliveries, and lead to one or more invoices.
If the process is flattened into only one case notion, several issues can appear:
This is why some processes need a different view. When the process is shaped by relationships between several objects, the case-centric model can become too narrow to represent the current state accurately.
This approach starts from a different assumption than traditional case-centric mining. Instead of asking, “What is the one case for this process?” it asks, “Which business objects are involved, and how are they connected?”
That shift matters because the analysis no longer depends on forcing all events into one process instance. Instead, it keeps the structure of the process closer to how it exists in reality.
In many business processes, several object types matter at the same time. A single process may involve a sales order, order items, deliveries, invoices, and returns. Each of these objects has its own lifecycle, but they are also connected.
Object-centric mining keeps those object types separate while still showing how they relate.
Typical object types might include:
This makes it easier to understand processes that split, merge, or branch across several related records.
One of the key differences is that a single event can be linked to several objects at once. That is important because many real process events do not belong neatly to just one case.
For example, an event such as create shipment may be related to:
This helps preserve the real structure of the process instead of flattening it into one narrow view.
In traditional mining, the focus is often on event sequence inside one case. Here, the relationships between objects matter just as much as the events themselves.
That means the analysis looks not only at what happened and when, but also at how different objects connect and influence one another across the process.
This is what makes the technique useful for more complex operational processes. It allows teams to see the process as a connected system of events and objects, rather than as a single event stream forced into one case definition.
An object centric data model is the structure used to represent the objects, events, and relationships that shape a process. It is what makes object-centric mining possible.
Instead of organizing the process around one case ID, this model shows which object types exist, which events happen, and how those events relate to one or more objects.
At a practical level, the model usually brings together three elements:
This allows the dataset to reflect the real structure of the process rather than simplifying everything into one case.
A simple order-to-cash structure might include these object types:
And the event relationships could look like this:
| Event | Related objects |
|---|---|
| Create sales order | Sales order, Order item |
| Confirm item | Order item |
| Create shipment | Shipment, Order item |
| Issue invoice | Invoice, Sales order |
| Return item | Order item, Shipment |
This kind of structure shows that one event can belong to more than one object, and that different objects have related but distinct lifecycles.
A traditional flat event log usually tries to group all events under one case notion. That can work well in simpler processes, but it becomes harder when several objects are equally important.
An object-centric data model keeps those objects separate and connected. This makes the analysis better suited to processes where:
This approach does not make every process easier. It makes complex processes more realistic to analyze because the dataset keeps the structure that already exists in the business.
This approach becomes easier to understand when it is tied to a real business process. A good example is order-to-cash, because this process often involves several related business objects at the same time.
A customer may place one order, but that order can include multiple items. Those items may be shipped separately, invoiced at different times, and in some cases returned individually. From a business point of view, all of this still belongs to the same broader process. From a data point of view, however, it is not a simple one-case sequence.
In a case-centric model, the team would need to choose one case notion. That might be:
Each choice gives a different view, but none of them fully captures the relationships between all the objects involved.
If the sales order is used as the case, item-level detail may be flattened. If the invoice is used as the case, the connection to shipments and items may become harder to interpret. This is where the process can start to look cleaner than it really is.
An object-centric view keeps those related objects visible instead of collapsing them into one stream.
In this example, the analysis can preserve the relationships between:
That makes it easier to understand how the process actually behaves across the full set of related objects.
For example, teams can see whether:
This gives a more realistic view of the process than a single case notion can provide.
This kind of complexity is common in real operations. It appears not only in order-to-cash, but also in procurement, manufacturing, and service processes where several objects interact at once.
The value of this technique is that it helps teams analyze those processes without losing the structure that makes them difficult in the first place.
This approach can represent complex processes more realistically, but it also introduces more complexity in the data and the analysis. That means it is not always the easiest option to apply, especially for teams that are new to process mining.
The biggest challenge usually appears in the data layer. Teams need to identify the right object types, events, and relationships before analysis can begin.
This often takes more effort than case-centric mining because the dataset must preserve how several objects connect instead of reducing everything to one case.
An object-centric view is often more accurate, but it can also be harder to understand at first. Teams need to think beyond one linear process instance and work with a structure where several object lifecycles interact at once.
That makes the approach more demanding for stakeholders who are used to simpler process views.
Some processes are simple enough that one case notion works well. In those situations, adding an object-centric model can create unnecessary complexity.
This means teams need to be deliberate. The goal is not to use the most advanced method available, but to use the one that best fits the process.
The analysis depends on defining the right object types and keeping those definitions consistent. If the object model is weak or unclear, the resulting view can become difficult to trust.
This is why object-centric mining works best when teams have enough process and data understanding to model those relationships correctly.
As part of process discovery, this approach helps teams understand complex current-state relationships that are difficult to capture with a single case-centric view alone.
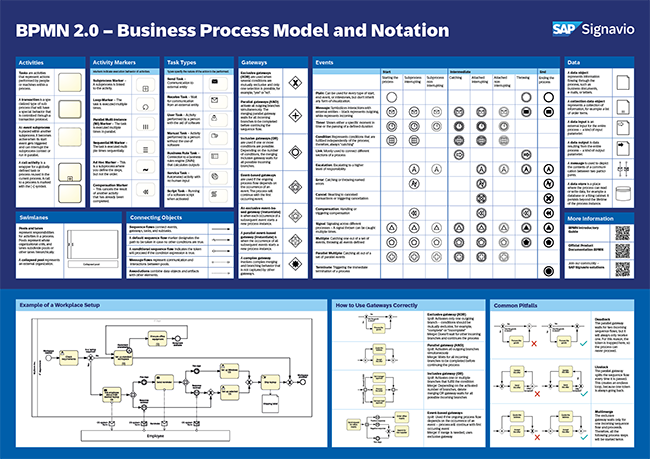
Get a BPMN 2.0 overview poster with the various graphical elements, examples of applications, and their meaning.